
Using LM Studio to Run LLMs Easily, Locally and Privately

Break free from limited cloud-based AI models that are too pricey and do not respect your privacy by installing LLMs directly on your computer. This empowers you with greater control over your data, all without relying on big tech companies.
My previous articles explored building your own Private GPT or running Ollama, empowering you with advanced open source LLMs. However, these solutions often require running lengthy commands in the terminal.
LM Studio streamlines the process entirely. Imagine a user-friendly application akin to the familiar interface of ChatGPT, where you can effortlessly download and utilize various Large Language Models.
Installing LM Studio on Linux
LM Studio provides an AppImage for Linux users. If it’s your first time installing an AppImage program, you can read our AppImage guide.
You can download the AppImage from the LM Studio website’s homepage.
Exploring LM Studio
Now let’s explore the LM Studio and try running some AI models for fun:
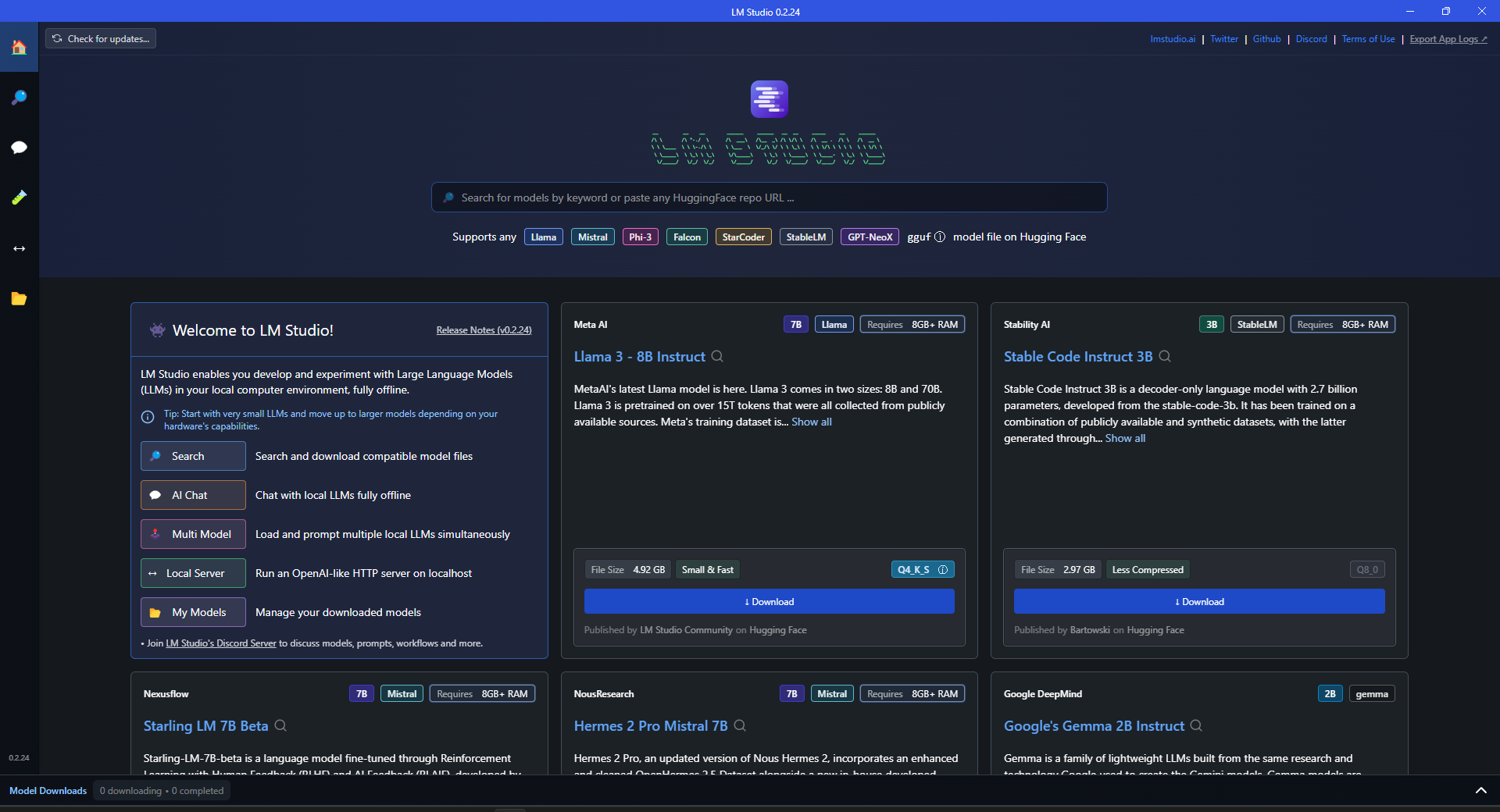
As you can see, on the top we have a search bar to look for any AI models, you can even paste the direct URLs of repositories from Hugging Face.
Downloading the first AI Model
It is quite easy to download AI models in LM Studio. Just search for the model, look for the relevant specs and requirements, and download it.
For example, I am running this on my laptop with 16GB RAM on a Ryzen 5 5500U with no dedicated GPU; thus, I would look for some small models with 2B to 7B instruct parameters.
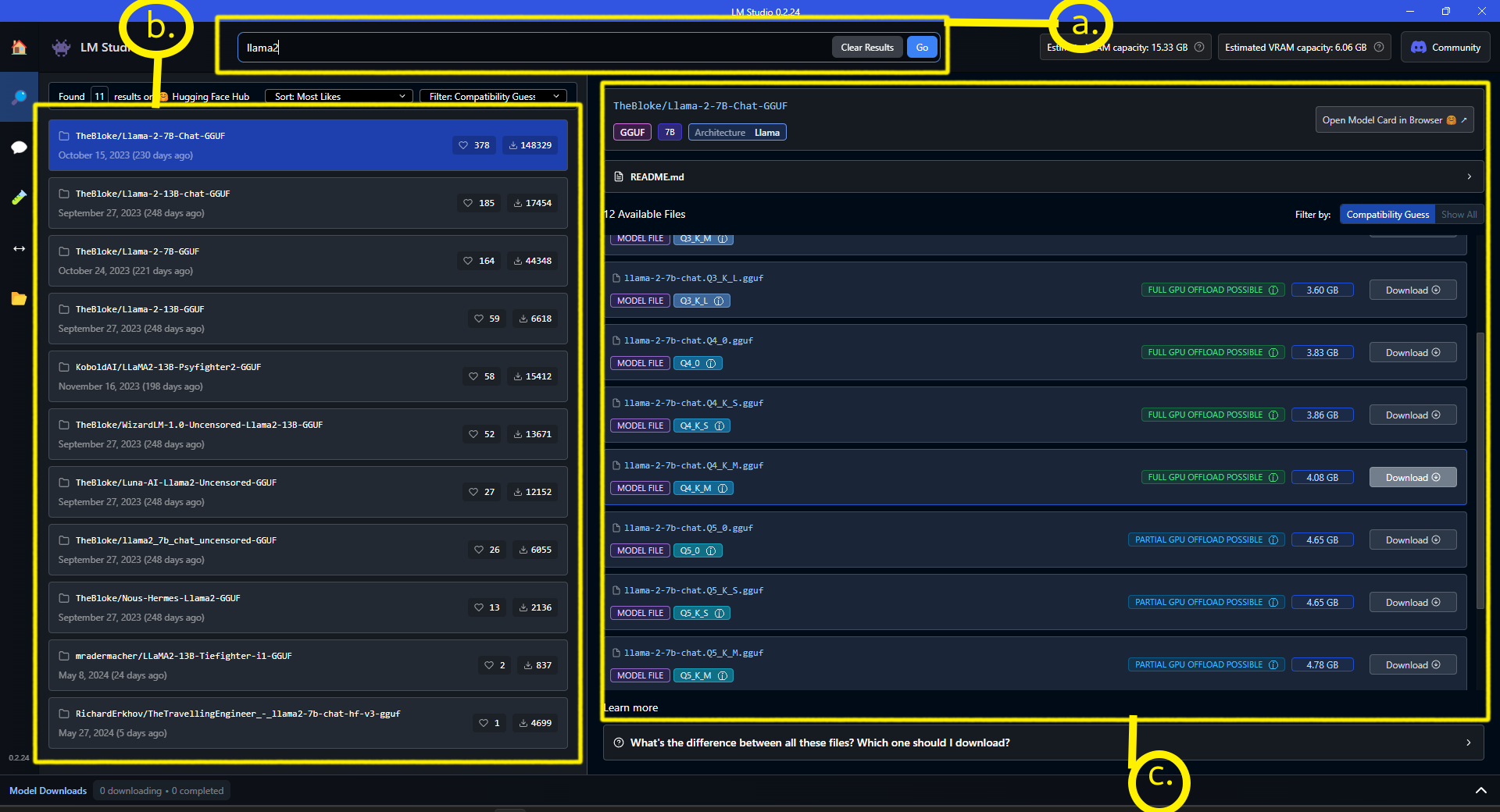
Okay all this information might intimidate you; let me explain what is happening here:
- I searched for the Llama 2 model in the search bar at the top
- The left pane shows you the different models relevant to your search
- Once a model is selected, you can see its specs and download options on the right pane
If you look closely, you will notice that there are four options that says “FULL GPU OFFLOAD POSSIBLE”. I will choose a model from those options only because LM Studio already analyzed my system resources and suggested the most suitable options.

Running LLaMA 2 model
Once an AI model has been downloaded, let’s start chatting with the LLM.
Load the model first and then all you have to do is go to the “Chat” section (chat bubble emoji in left), at the top, press the drop down menu that says “Select a model to load” and from below you can select any model you have downloaded.
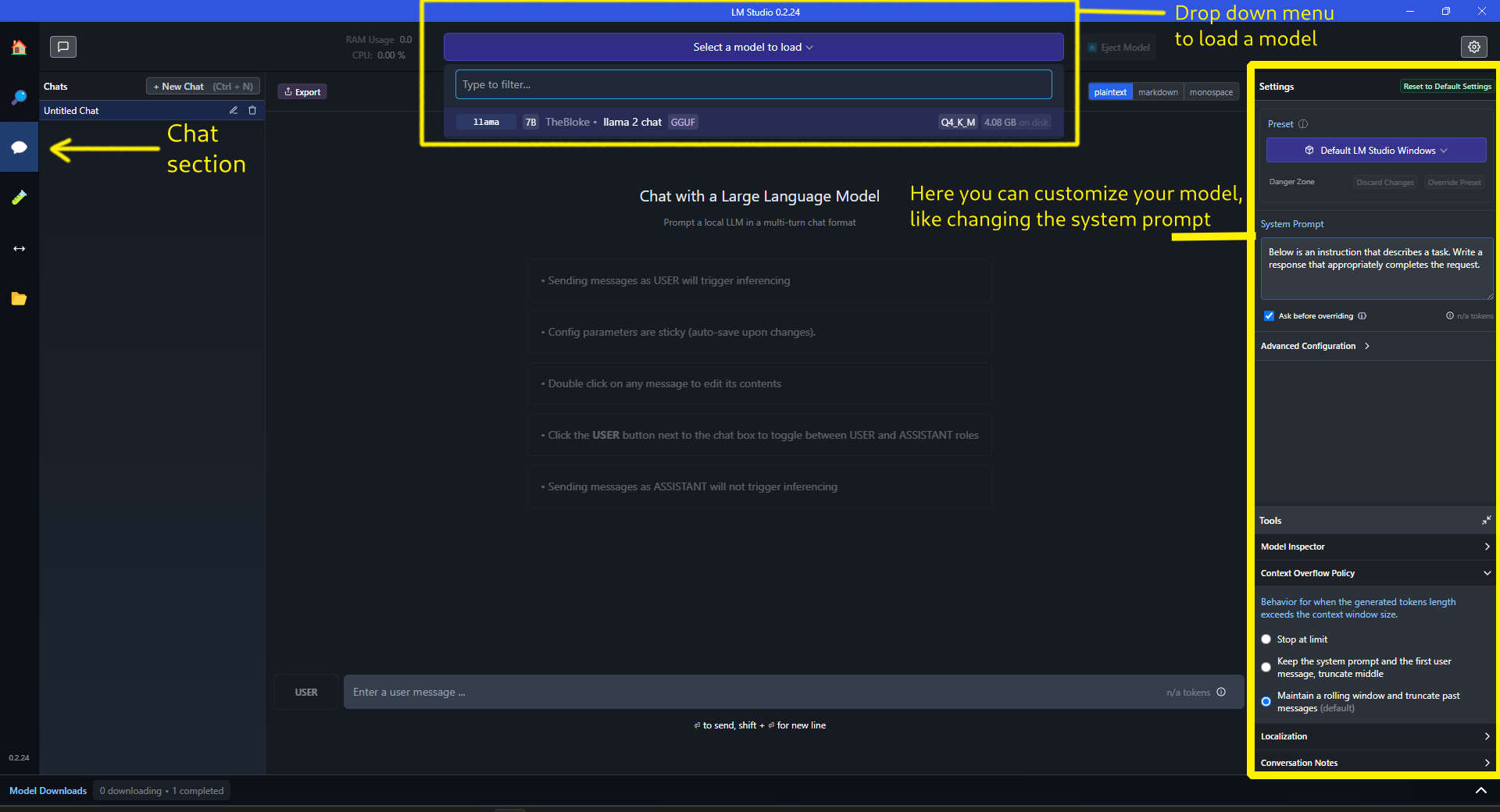
Now that you have selected your model, it’s time to chat with your personal, totally private, offline AI assistant.
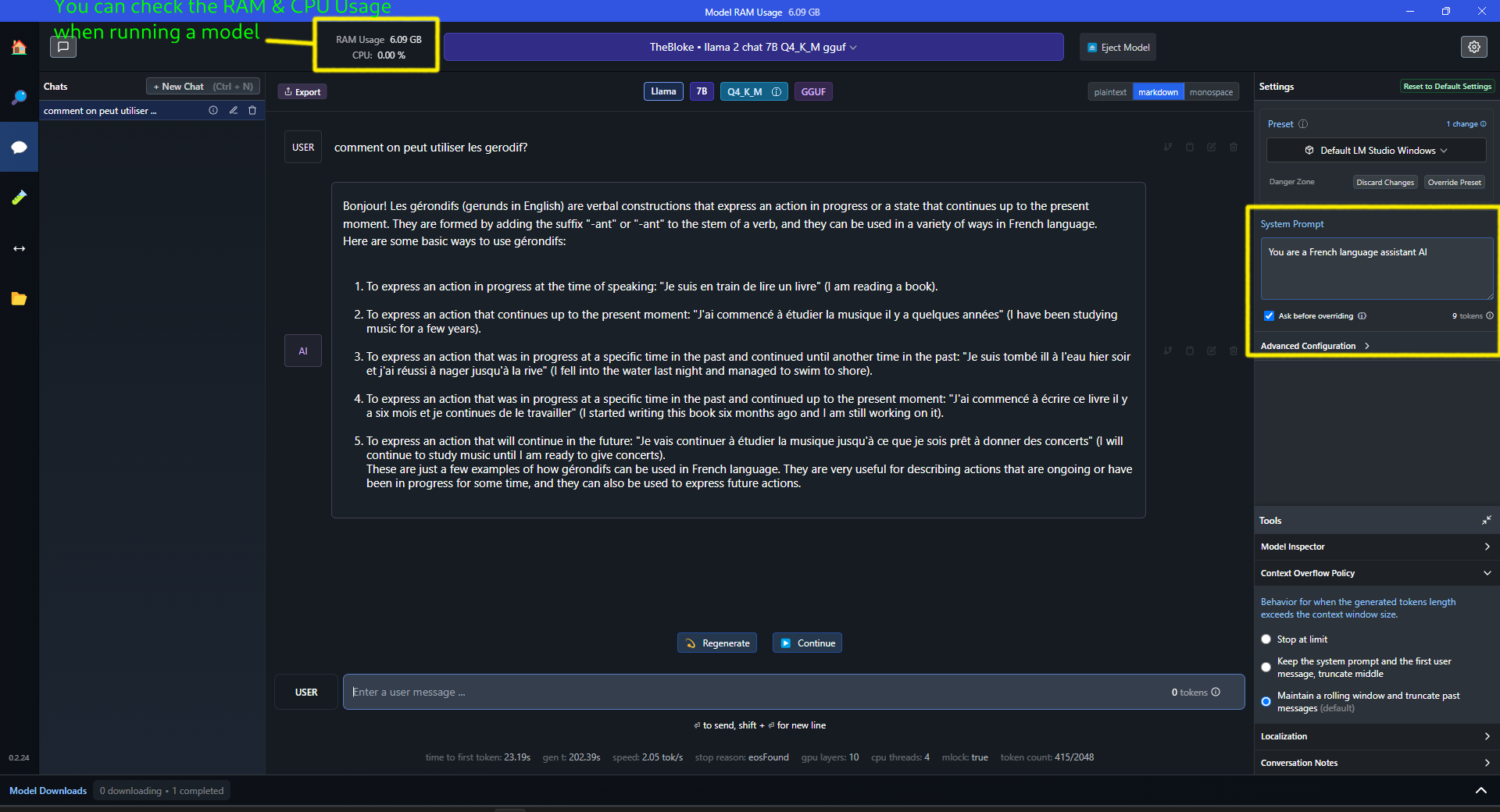
I have changed the default system prompt to a personalized one i.e. “You are a French language assistant AI” and I must say, the response was quite accurate.
I know that was a prompt you weren’t expecting, but I’m learning French, so bear with me.
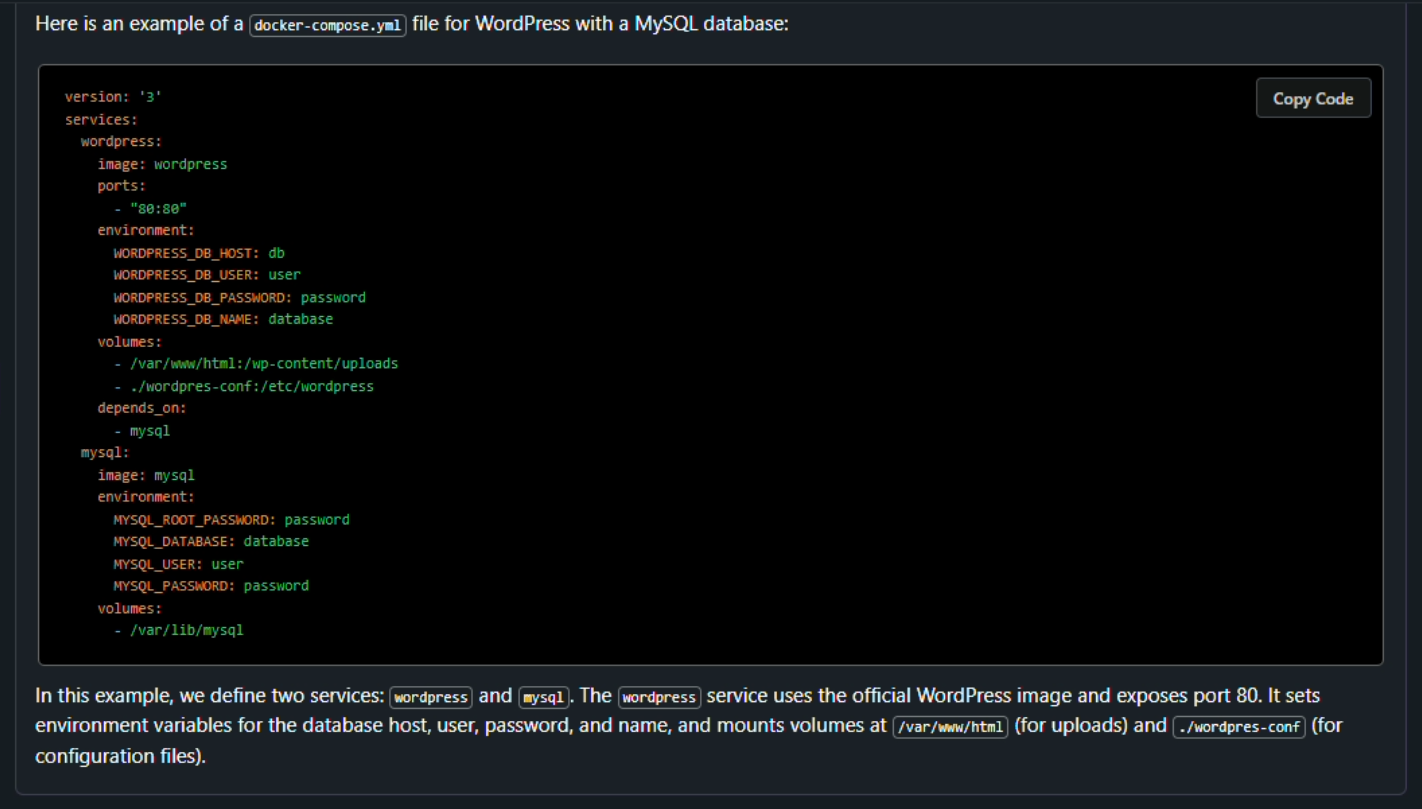
Let’s ask our model to write a docker-compose file for WordPress with MySQL database:
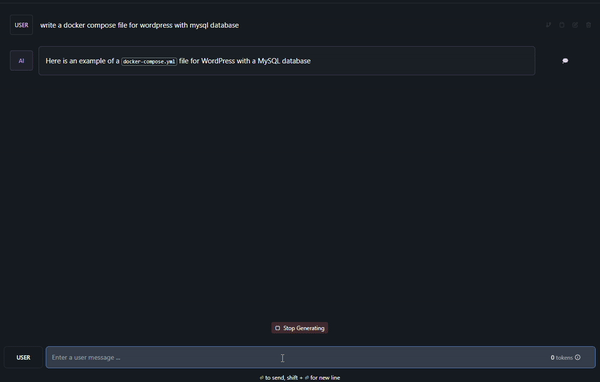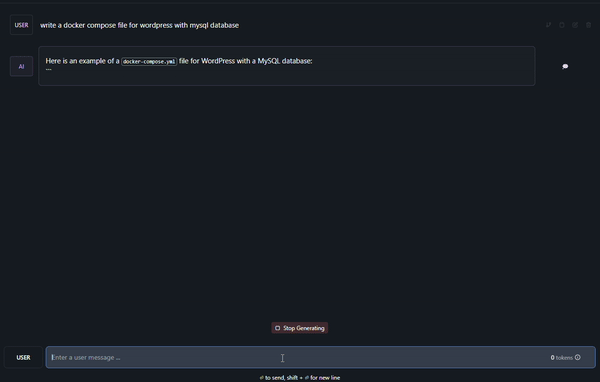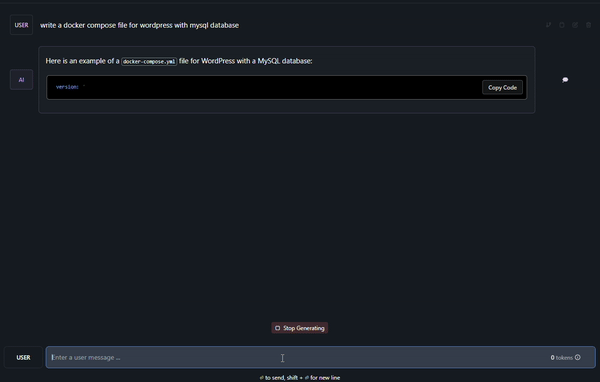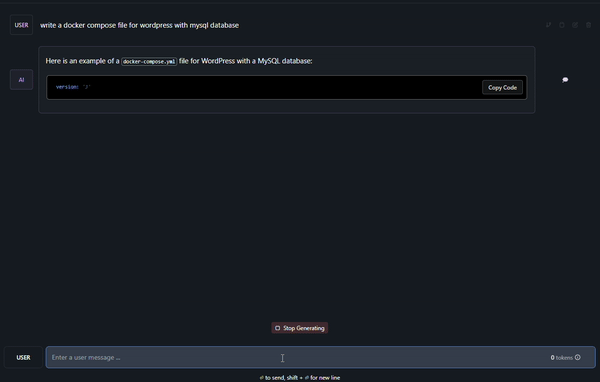
It’s already been a minute and it’s still going:
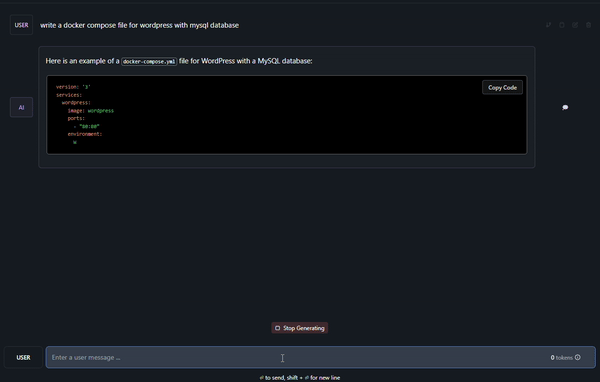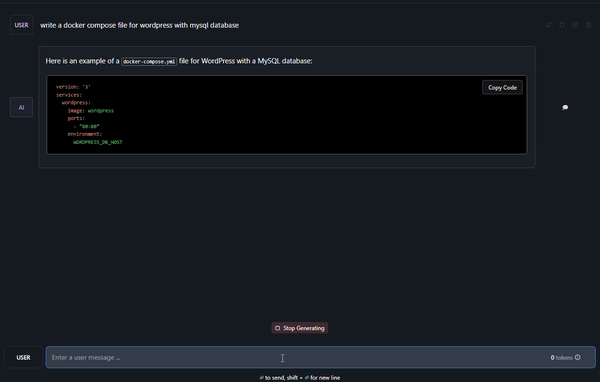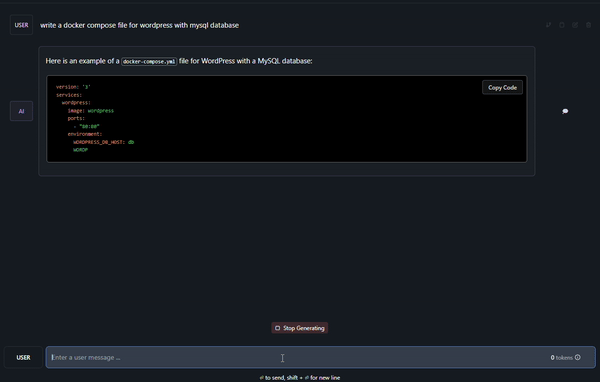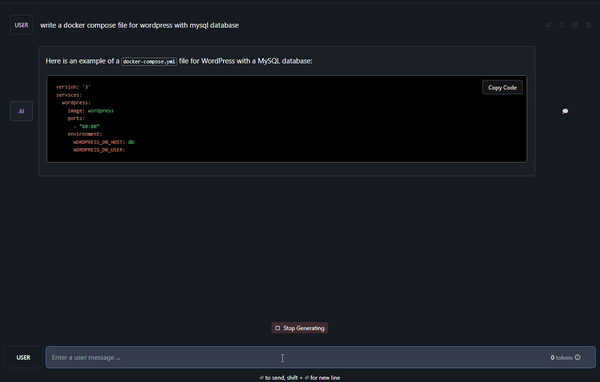
Okay, I don’t want you guys to feel the pain of waiting for it to finish. It took 4 minutes and 56 seconds. No wonder AI computing is expensive. You need good hardware (read GPU).
This was the response if you are wondering:
Final Thoughts
If you have a powerful system with plenty of RAM and dedicated GPU(s), I highly recommend installing LM Studio.
You have full control over your data since it runs locally on your machine. LM Studio also features a user-friendly interface and allows you to experiment with the latest AI models beyond what companies typically offer. This is truly a win-win situation.
And yes I am well aware the system I use for testing was quite slow but I was targeting the average Joe and yes I will try to run this on a Raspberry Pi because why not, that is the fun of tinkering with technology.
If you have suggestions for more AI tools, feel free to comment.